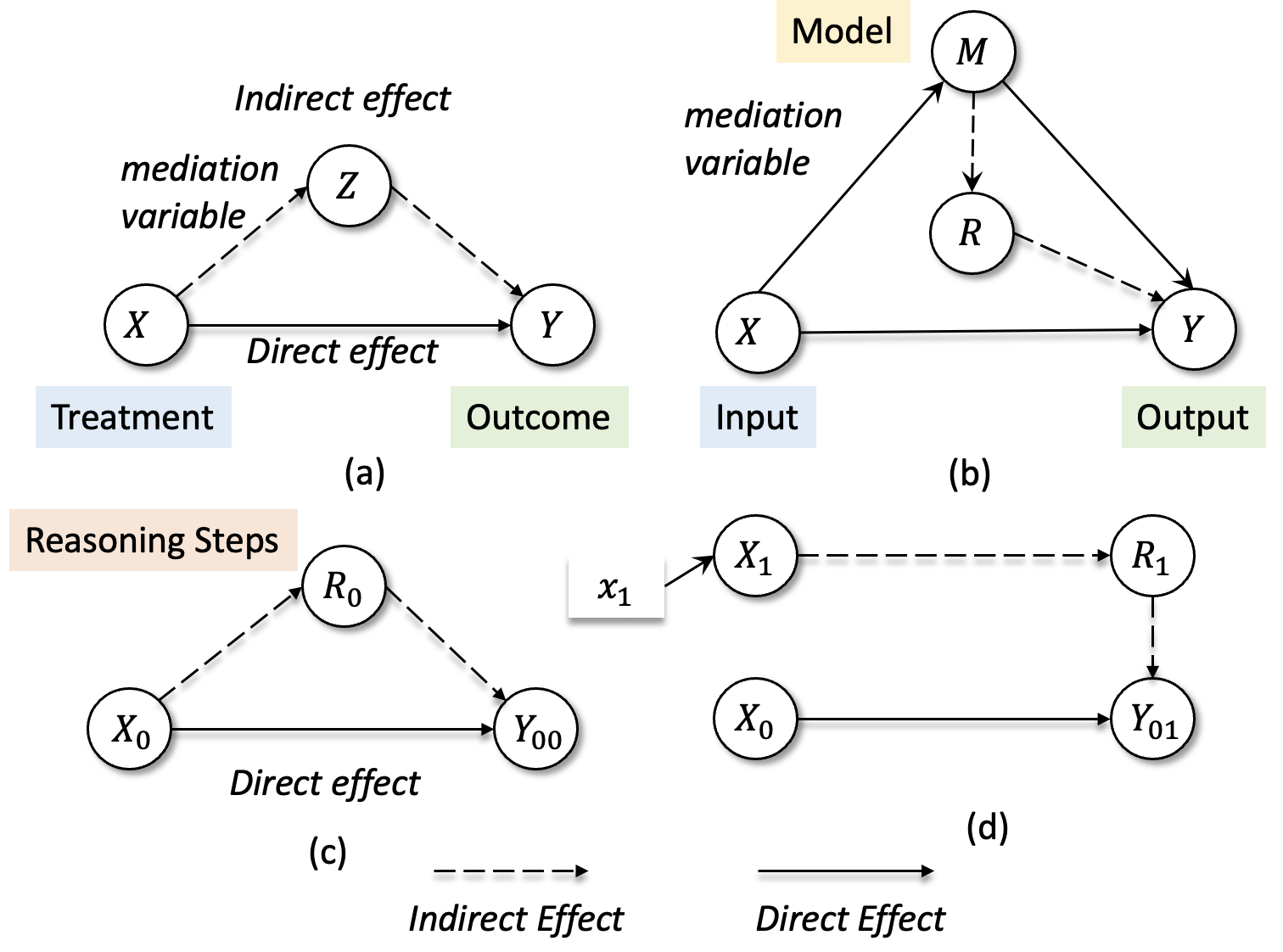
Figure 1. An example of our proposed causal analysis to measure the faithfulness of the final output with respect to the CoT generated by the model. We perturbed CoT rationales and studied the causal impact on the model's behaviour.
Chain-of-thought (CoT) reasoning techniques have been shown to improve the performance of large language models (LLMs) by generating step-by-step reasoning traces before generating a final answer. In standard CoT, LLMs can generate plausible explanations, with the final answer not necessarily guaranteed to follow the reasoning chain or imply a causal relation between the reasoning chain and the model’s outcome.
We use the Causal Mediation Analysis method to measure and interpret the contribution of a reasoning chain (mediator) to the final answer (observed output). Our causal study highlights two issues: (i) LLMs can generate an unfaithful and implausible reasoning chain, and (ii) LLMs are inconsistent when reasoning over their own generated reasoning traces.
Finally, we introduce FRODO, a novel framework to tailor small-sized LMs to generate correct reasoning steps and robustly reason over these steps. FRODO consists of an inference module that learns to generate correct reasoning steps using an implicit causal reward function and a reasoning module that learns to faithfully reason over these intermediate inferences using a counterfactual and causal preference objective.
Causal Mediation analysis
Figure 2. Causal graph for natural language reasoning, where we model P(Y| do(x)). X0 = original reasoning problem, X1 = intervened reasoning problem, R0 = reasoning steps for X0 reasoning problem, R1 = reasoning steps for X1, Y = output, and M = model parameters
Reasoning Chain as Mediator
In this work, we view the reasoning process as a causal graph, framing the input (reasoning problem) X and the output Y as random variables and the reasoning steps as mediator variable R.
We use mediation analysis to interpret the role of reasoning steps as mediators between model inputs and model outputs. Please note that there are two mediator variables, model parameters M and reasoning steps R (see above Figure 2(b)).
However, in this work, we are interested in understanding the indirect effect of R on the output Y; hence, we assume model parameters M to be fixed.
Let X0 denote the initial reasoning problem, R0 as the reasoning chain given X0, and Y00 denote the potential outcome if the treatment variable and mediator variable are X0 and R0, respectively.
Whereas Y01 denotes the possible outcome when treatment is set to X0 and R1 is the reasoning chain for an intervened reasoning problem (see Figure 2(d)).
Analysis Outcomes
Our study suggests that vanilla LMs (<20B) (in a zero-shot setting) are systematically unfaithful and consistently fail to reason over the mediator.
In general, our experiments show a large variation in the causal effects of COT in the final answer depending on the tasks.
Models that are instruction-tuned or trained on the chain of thought during the pre-training phase have a better indirect effect across different reasoning tasks, suggesting that fine-tuning on CoT can make the model more faithful. Interestingly, we observe that there is an inverse scaling for certain tasks.
In our case, the indirect effect is worsening with increasingly capable models, indicating that smaller models might be more effective in faithful reasoning.
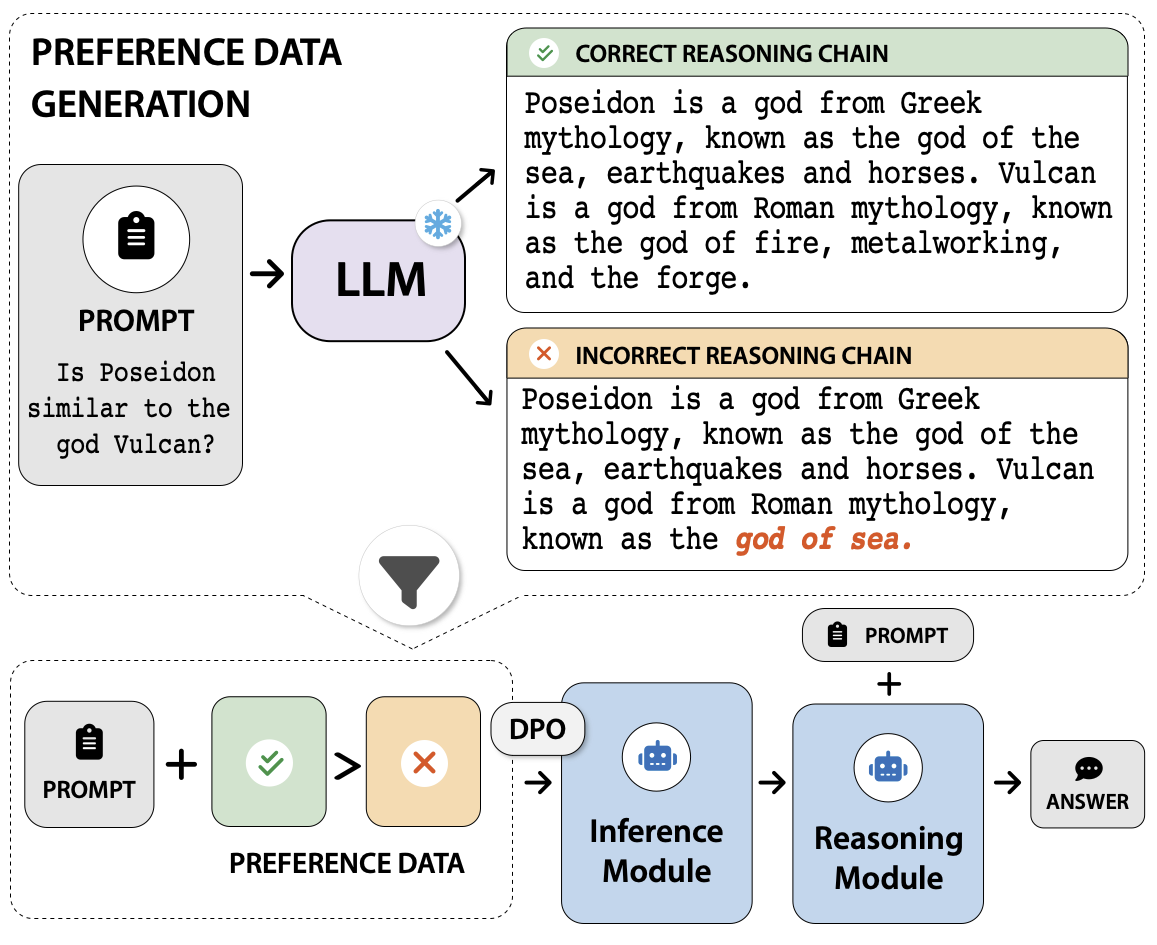
An overview of the FRODO framework. It comprises two modules: (i) Inference Module and (ii) Reasoner Module.
FRODO
We propose a new framework, FRODO, that focuses on tailoring small-sized LMs (<5B parameters) to be strong rationalizers and perform reasoning faithfully over the rationales. FRODO aims to improve the synergy between the reasoning chain and the final answer.
Inference Module: The first module tailors small-sized LMs to generate correct reasoning chains (inference module), while the second module takes the reasoning chains as input and faithfully reasons over them to arrive at the correct answer (reasoning module).
To learn to generate correct reasoning chains, we use the DPO algorithm, which enables the model to prefer correct reasoning chains over counterfactual ones with implicit feedback. Instead of relying on human labelling, we obtain preference data by prompting LLMs to generate correct and counterfactual reasoning chains.
Reasoner Module: In this module, we train another small-sized LM to improve the causal effect between the reasoning chain and the final answer using a counterfactual and causal preference ranking objective.
Results summary
Causal Analysis
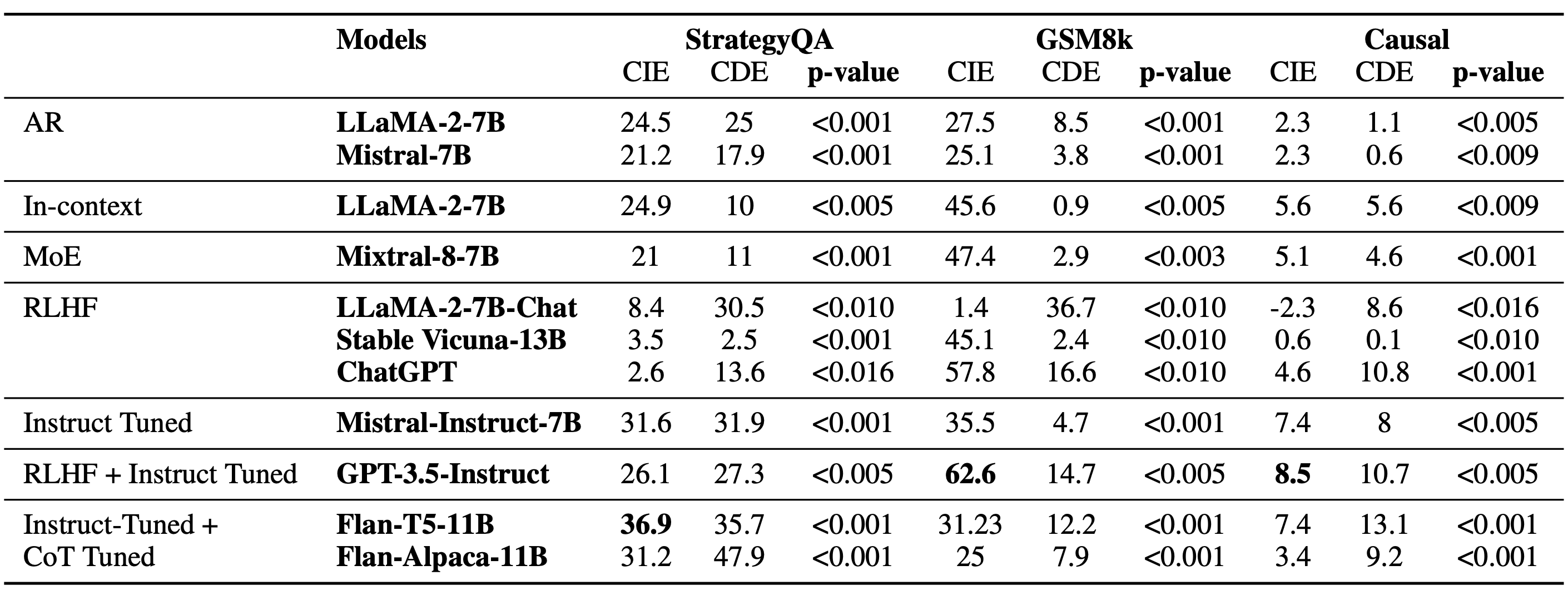
Table 1 shows the results of causal mediation analysis for 11 different LMs.
In these experiments, we examined the causal behaviour using reasoning chains generated by GPT-4 (controlled setting).
We find that in-context learning and instruction-tuning improve the indirect effect over models trained only with language modelling objectives (e.g., LLaMA and Mistral), indicating that these methods help the model align better with the reasoning chains.
We observe that models trained with RLHF objective (ChatGPT, Llama-2-7B-Chat) have a more direct effect than an indirect effect, suggesting that training on human feedback might have disincentive faithful reasoning.
Interestingly, we observe that none of the models has high indirect or direct effects on the causal understanding task.
One intuitive reason is that the causal understanding task is challenging, and the model's (<10B) performance is nearly random; hence, the effects are not strong.
Overall, we observe that LLMs are inconsistent in faithfully performing reasoning over the CoT.
Table 1. Causal Effects of CoT. The reported results are zero-shot performance. CIE: Controlled Indirect Effect, CDE: Controlled Direct Effect.
Table 2 shows the zero-shot performance of the ChatGPT and GPT-4 models. We observe that for StrategyQA and Causal Understanding tasks,
GPT-4 has a higher natural indirect effect than ChatGPT, suggesting that it is able to better reason over the reasoning steps for these tasks.
However, for mathematical reasoning (GSM8K), ChatGPT has a better indirect effect. Qualitatively, we find that for mathematical reasoning, when we provide intervened reasoning steps, GPT-4 considers them incorrect and continues to generate correct reasoning steps.
This results in a lower indirect effect score.
Moreover, GPT-4 exhibits a more pronounced direct effect than Chat-GPT, suggesting that its outputs are more causally sensitive to reasoning problems.
Table 2. Causal Effects of generated CoT and reasoning problems on the outputs, with both Natural Indirect Effect (NIE) and Natural Direct Effect (NDE).
FRODO results
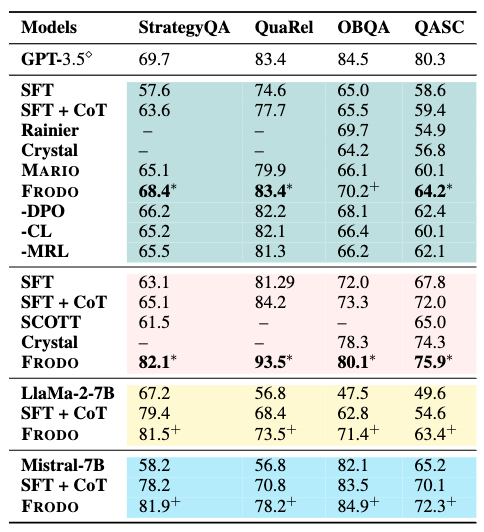
We evaluate FRODO on four reasoning tasks (Quarel, StrategyQA, OpenBookQA, QASC) using multiple model backbones of different scales and demonstrate that \ourmodel achieves an absolute accuracy improvement of 2%~3% over baselines trained with standard supervised fine-tuning or chain-of-thought distilled methods.
FRODO improves the robustness and generalization ability of the reasoning LM, yielding higher performance on out-of-distribution test sets.
Table 3.
Performance of small-sized LMs (770M-7B) on four different reasoning tasks. The base models are Teal Color: {T5-large} (770M), Pink Color: {T5-3B} (3B), Yellow Color: {LLaMa-2-7B} and Cyan Color:{Mistral-7B} . We report accuracy (\%).
Figure 3. FRODO is learning from a Large Lange Model to generate correct reasoning steps and final answer.
BibTeX
@misc{debjit2024frodo,
title={Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning},
author={Debjit Paul, Robert West, Antoine Bosselut and Boi Faltings}
year={2024},
eprint={2402.13950},
archivePrefix={arXiv},
primaryClass={cs.CL}
}